Website Fingerprinting using Deep Learning

Introduction
Website fingerprinting is a technique that classifies network traffic data into specific websites based on distinct characteristics such as packet size, timing, and number. This method creates a unique “fingerprint” for each website, allowing attackers to infer the web pages a user visits, even through encrypted connections.
Website fingerprinting can breach privacy even through encrypted connections like those provided by VPNs or Tor, highlighting the importance of advanced countermeasures.
In this research, a Convolutional Neural Network (CNN) was trained and evaluated for its effectiveness in website fingerprinting attacks. Established hyperparameters from previous studies (AWF, DF, DL) were utilized to gauge their impact on model performance.
The improvement in fingerprinting techniques poses a growing privacy threat, underscoring the need for continuous updates to encryption technologies.
The CNN model achieved a 10% improvement in accuracy when tested across the entire dataset.
Experimental Design
Four datasets with varying sample sizes were analyzed, each comprising multiple files labeled as X-Y, where X denotes the traffic site and Y the sample number. Network traffic data within these files were parsed into lists of values coded as ‘1’ or ‘-1,’ with ‘0’ used for padding, and the final value indicating the source site.
| Dataset | # of Sites | # of Samples per Site | Total Samples |
|---|---|---|---|
| small_10_100 | 10 | 100 | 1000 |
| large_10_1000 | 10 | 1000 | 10000 |
| large_95_100 | 95 | 100 | 9500 |
| full | 95 | 1113 (approx.) | 105730 |
When parsing network traffic data for analysis, ensure accurate labeling to maintain data integrity and reliability of the results.
The hyperparameters were selected based on comprehensive analysis, testing, and prior research contributions from scholars such as S. Dubey, S. Singh, B. Chaudhuri, D. Marcu, C. Grava, and others. The hyperparameters assessed included:
Proper selection of hyperparameters can significantly influence the performance of machine learning models, as demonstrated in this study.
| Hyperparameters | Search Range |
|---|---|
| Input Units | [1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000] |
| Optimization Function | [SGD, Adam, AdaMax, RMSProp] |
| Activation Function | [TanH, ReLU, SeLU, ELU, Sigmoid] |
| Batch Normalization | [No, Yes] |
| Dropout Layers | [None, 0.10, 0.30, 0.50, 0.70, 0.90, 0.93, 0.95, 0.97, 0.99] |
A breakdown of the evaluated hyperparameters and why they were selected for this assignment is as follows:
- Input Units: Refers to the total number of packet directions used as input for the model. The selection range for input units is from 1,000 to 10,000, aimed at identifying the ideal number for optimal performance. In previous studies, Rimmer et al. utilized 3,000 input units for their website fingerprinting (WF) classification model, whereas Sirinam et al. employed 5,000 input units.
- Optimization Functions: These functions are crucial in the learning process of a CNN model as they guide the optimization process and significantly affect the model’s performance. The options include Stochastic Gradient Descent (SGD), Adam, AdaMax, and RMSProp. Research indicates that AdaMax performed best in the study by S. Vani and T. Rao, Adam was found to be most effective by S. Bera and V. Shrivastava, and D. Marcu and C. Grava reported the highest performance with SGD. Rimmer et al. used RMSProp, while Sirinam et al. opted for AdaMax in their respective WF models.
- Activation Functions: These mathematical functions are applied to outputs from model nodes, introducing non-linearity to the network. The types considered were Hyperbolic Tangent (TanH), Rectified Linear Unit (ReLU), Scaled ELU (SELU), Exponential Linear Unit (ELU), and Sigmoid. ReLU is noted for superior performance in image classification per S. Dubey, S. Singh, and B. Chaudhuri, while Sigmoid and TanH were least effective. ELU was favored by D. Marcu and C. Grava. Rimmer et al. incorporated ReLU, and Sirinam et al. used a combination of ReLU and ELU in their models.
- Batch Normalization(BN): Used to standardize inputs to a network, batch normalization enhances learning speed, provides regularization, and helps reduce overfitting. Studies by C. Garbin, X. Zhu, and O. Marques show that BN improves accuracy in CNNs with minimal training time impact. Rimmer et al. did not use BN in their WF model, whereas Sirinam et al. implemented several BN layers.
- Dropout Layers: These layers help prevent overfitting by temporarily deactivating a certain percentage of neurons during each training iteration. The range of dropout rates tested included None, 0.1, 0.5, 0.7, 0.9, and finer increments up to 0.99. Research by Srivastava et al. supports the effectiveness of dropout in enhancing neural network performance on supervised tasks, although studies by C. Garbin, X. Zhu, and O. Marques found that higher rates could diminish accuracy. Rimmer et al. employed a dropout rate of 0.1, while Sirinam et al. used a mixture of rates (0.1, 0.5, 0.7) in their model configurations.
| Hyperparameters | Default | AWF | DF |
|---|---|---|---|
| Input Units | 2000 | 3000 | 5000 |
| Optimization Function | SGD | RMSProp | AdaMax |
| Activation Function | TanH | ReLU | [ELU, ReLU] |
| Batch Normalization | No | No | Yes |
| Dropout Layers | 0.50 | 0.10 | [0.10,0.50,0.70] |
The default model was used to test and train hyperparameters. The AWF model was created based on the research by Rimmer et al., while the DF model was based on the research by Sirinam et al. Each hyperparameter was updated on the default model to create new models and identify the best hyperparameter values. To ensure consistency and accuracy in our results, each model was executed on the full dataset three times. The accuracy percentage and loss of each model were evaluated and compared with other hyperparameter values. After analyzing the results, we selected the best hyperparameters to construct the ‘Best’ model.
Results
| Hyperparameter | Value | Accuracy (%) |
|---|---|---|
| Input Units | 1000 | 65.42 |
| 2000 | 75.62 | |
| 3000 | 77.21 | |
| 4000 | 77.75 | |
| 5000 | 77.73 | |
| 6000 | 77.17 | |
| 7000 | 77.26 | |
| 8000 | 79.20 | |
| 9000 | 78.87 | |
| 10000 | 77.40 | |
| Optimization Function | SGD | 76.28 |
| Adam | 68.39 | |
| AdaMax | 73.31 | |
| RMSProp | 59.22 | |
| Activation Function | TanH | 76.37 |
| ReLU | 76.70 | |
| SeLU | 74.13 | |
| ELU | 76.00 | |
| Sigmoid | 69.07 | |
| Batch Normalization | No | 75.90 |
| Yes | 77.42 | |
| Dropout Layers | None | 72.79 |
| 0.10 | 74.69 | |
| 0.30 | 75.36 | |
| 0.50 | 76.44 | |
| 0.70 | 77.02 | |
| 0.90 | 78.76 | |
| 0.93 | 77.84 | |
| 0.95 | 75.20 | |
| 0.97 | 67.55 | |
| 0.99 | 37.78 |
The varying accuracy across different configurations shows the critical role of each hyperparameter in the model’s performance.
The following is a breakdown of the results for each of the hyperparameters:
- Input Units: The model configured with 8,000 input units demonstrated superior performance compared to others. While input units in the range of 3,000 to 9,000 showed roughly similar accuracy levels, 8,000 units slightly outperformed the rest. This finding suggests a diminishing return on accuracy improvements beyond a certain threshold of input units, highlighting a balance between essential and redundant data within the inputs.
- Optimization Function: Stochastic Gradient Descent (SGD) outperformed other optimization functions, closely followed by AdaMax. Conversely, Adam and RMSProp showed significantly poorer performance. This outcome supports the efficiency of SGD, aligning with findings by D. Marcu and C. Grava that it is a superior optimization method, providing faster convergence to optimal solutions.
- Activation Functions: The Rectified Linear Unit (ReLU) activation function outshone others in these tests, whereas the Sigmoid function performed the poorest. These results endorse the suitability of ReLU for this application due to its effectiveness in enhancing model convergence. This supports the assessments by S. Dubey, S. Singh, and B. Chaudhury regarding ReLU’s superiority and the ineffectiveness of Sigmoid.
- Batch Normalization: Models employing Batch Normalization demonstrated better performance than those without it, indicating that BN contributes to regularization and helps prevent overfitting, thereby improving accuracy. This supports the claims by C. Garbin, X. Zhu, and O. Marques regarding the benefits of BN in enhancing model effectiveness.
- Dropout Layers: Models with a dropout rate of 0.9 outperformed those with other rates. While dropout rates between 0.1 and 0.7 achieved similar accuracy levels, models with lower rates reached peak accuracy more swiftly than those with higher rates. However, increasing the dropout rate beyond a certain point was counterproductive, as higher rates resulted in lower accuracy, indicating a limit to the effectiveness of increasing dropout to improve performance.
Using high dropout rates might lead to underfitting, where the model fails to learn adequately from the training data.
Based on our experiments, we have found that certain hyperparameters deliver the most promising results. These include Input Units set to 8000, the use of SGD as the optimization function, ReLU as the activation function, inclusion of Batch Normalization, and a dropout layer rate of 0.9.
These hyperparameters were crucial in creating our ‘Best’ model, which we compared with the previous three models.
| Model | Accuracy (%) |
|---|---|
| Default Model | 73.68 |
| Best Model | 83.02 |
| AWF Model | 80.70 |
| DF Model | 93.12 |
Notably, the DF model outperforms the other models significantly in terms of both accuracy percentage and loss, followed by the ‘Best’ model, while the ‘Default’ model performs the poorest. In addition, the ‘Best’ model demonstrates approximately 10% higher accuracy than the ‘Default’ model in the full dataset and exhibits a reduction in loss by 0.3.
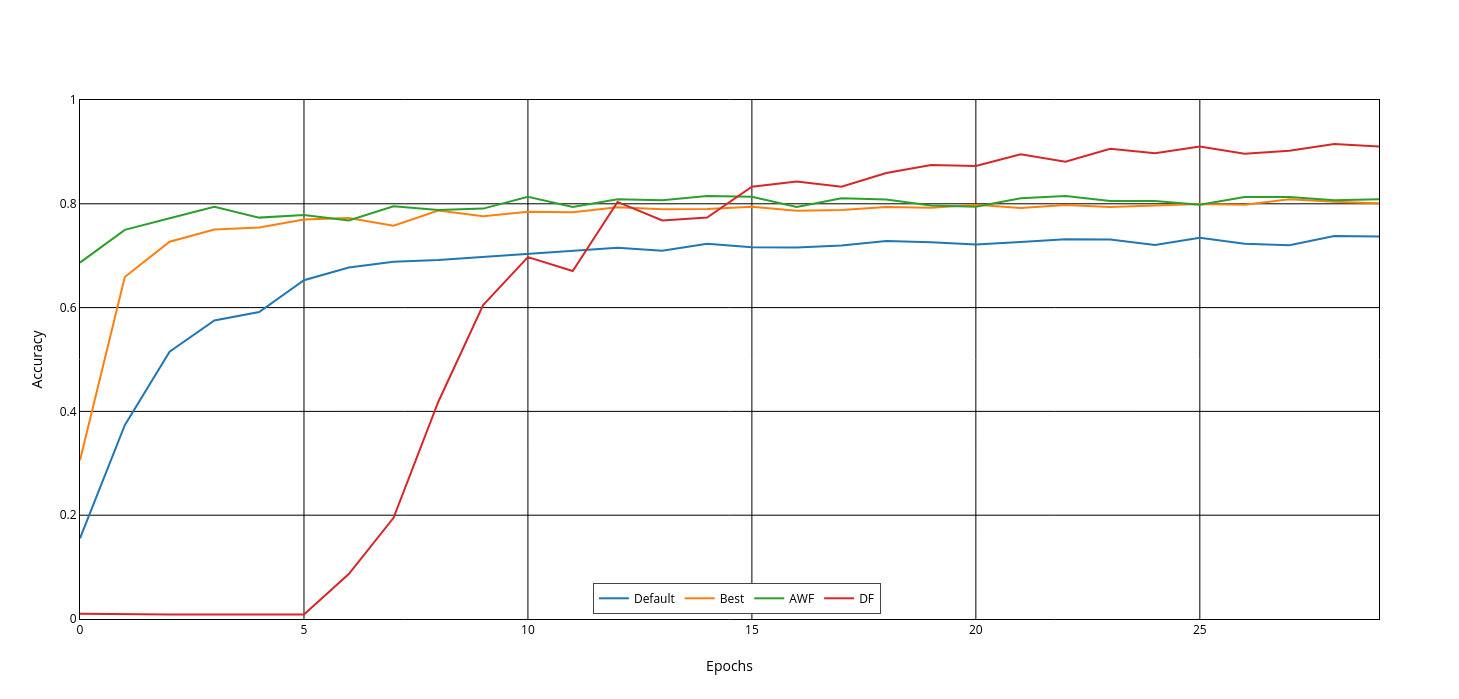 Accuracy over Epochs for CNN
Accuracy over Epochs for CNN
This illustrates the classification accuracy of website fingerprinting undefended traffic using a CNN in a closed-world experiment, where the tested models’ accuracy is observed over multiple epochs.
The graph shows that, for all models, the accuracy improvements are less noticeable after 25 epochs.
The figure indicates that the AWF model reaches its peak accuracy the fastest, followed by the ‘Best’ model, and the ‘DF’ model takes the longest. However, the DF model catches up and surpasses the other models in about 15 epochs. We can also see a significant improvement in the ‘Best’ model compared to the ‘Default’ model, consistently providing higher accuracy and quicker delivery.
The ‘Best’ model was constructed by varying only a few hyperparameters of the ‘Default’ model. This model could be further improved by modifying other hyperparameters, such as the number of hidden layers, the density of hidden layers, filters and filter sizes, and convolutional layers.
Further adjustments to other model parameters like the number of hidden layers or convolutional layers could provide additional gains in model performance.
Acknowledgement
This project was a joint effort with my skilled colleagues, Zhi Liu and Alex Sutay. Together, we developed implementations of CNN, SDAE, and LSTM, and shared the dataset as part of our assignment for the CSEC-720 Deep Learning Security course at RIT.
You can access the project by clicking here and my code by clicking here.
References
- Rimmer et al. - Automated Website Fingerprinting through Deep Learning
- Sirinam et al. - Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning
- Kota Abe, Shigeki Goto - Fingerprinting attack on Tor anonymity using deep learning
- Dubey et al. - Activation functions in deep learning: A comprehensive survey and benchmark
- David C. Marcu, Cristian Grava - The impact of activation functions on training and performance of a deep neural network
- S. Vani, T. V. Madhusudhana Rao - An Experimental Approach towards the Performance Assessment of Various Optimizers on Convolutional Neural Network
- Somenath Bera, Vimal Kumar Shrivastava - Analysis of various optimizers on deep convolutional neural network model in the application of hyperspectral remote sensing image classification
- Garbin et al. - Dropout vs. batch normalization: an empirical study of their impact to deep learning
- Srivastava et al. - Dropout: a simple way to prevent neural networks from overfitting