Types of Black-box Adversarial Attacks on Deep Learning

In the rapidly evolving world of artificial intelligence, the integrity and robustness of machine learning models are paramount. An intriguing facet of AI security is the concept of adversarial attacks, where malicious inputs are designed to deceive neural networks into making erroneous predictions or classifications. These attacks are not just theoretical concerns; they represent significant practical challenges in deploying AI systems in sensitive environments.
Adversarial attacks pose a significant challenge to the deployment of AI systems in critical environments like healthcare and autonomous driving, where security and accuracy are crucial.
Categories of Adversarial Attacks
Adversarial attacks can be categorized based on the attacker’s access to the model:
- White Box Attacks: The attacker has complete knowledge of the model, including its architecture and weights.
- Grey Box Attacks: The attacker partially knows the model.
- Black Box Attacks: The attacker cannot access the model’s internals and must operate without knowing the underlying details.
Understanding the type of access an attacker has to a model is key to implementing effective security measures. Familiarize yourself with the differences between white, grey, and black box attacks to better protect your systems.
Given these constraints, black-box attacks are particularly notable because they represent common real-world attack scenarios where the attacker does not have insider information.
Types of Black-Box Attacks
Black-box attacks are primarily of two types: transfer-based and decision-based.
Black-box attacks are particularly challenging to defend against because they require no internal knowledge of the AI system, making them a common choice for real-world attacks.
Transfer-Based Attacks (TRA)
In transfer-based attacks, adversaries typically perform white-box attacks on a substitute model to generate adversarial examples. These examples are then used to attack the target model in a black-box manner. This method hinges on the assumption that similarities in model architectures can be exploited to transfer adversarial examples from one model to another.
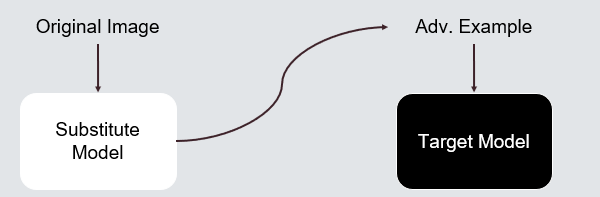 Transfer-based Attacks(TRA)
Transfer-based Attacks(TRA)
Transfer-based attacks rely on the assumption that different models behave similarly. This can lead to errors in defense strategies if not carefully managed.
Gradient-based Attack Methods: Among the most prominent is the **Fast Gradient Sign Method (FGSM) by Goodfellow, Shlens, and Szegedy. This method utilizes the gradients of the loss function with respect to the input image to produce perturbations. FGSM is known for its computational efficiency, as it requires only one forward and backward pass through the neural network.
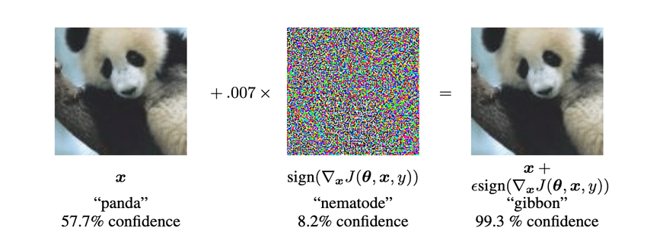 Fast Gradient Sign Method TRA Attack
Fast Gradient Sign Method TRA Attack
- ** Optimiztion-based Attack Methods **: Another potent method is the ** Carlini & Wagner ** (C&W) attack. This attack defines an objective function that quantifies the success of the adversarial example, focusing on minimizing the difference between the perturbed and original inputs while ensuring misclassification. It also employs box constraints to keep pixel values within realistic bounds.
 Carlini & Wagner TRA Attack
Carlini & Wagner TRA Attack
Despite their effectiveness, transfer-based attacks often suffer from overfitting to the substitute model and issues with noise compression, which can limit their effectiveness against the target model.
 Overfitting due to TRA
Overfitting due to TRA
Overfitting occurs when adversarial examples are tailored too closely to the substitute model—differences in the model structure and decision boundaries mean these attacks are effective on the substitute model but fail to deceive the target model.
 Noise due to TRA
Noise due to TRA
Additionally, the problem of noise compression hinders the effectiveness of these attacks. In ideal scenarios, adversarial noises are optimized and compressed effectively across models; however, in the case of transfer-based attacks, the noise often only relates to the substitute model. This limitation prevents the adversarial examples from being generalizable and effective against the target model, showcasing the critical noise issue due to TRA.
Decision-based Attacks
These attacks do not rely on gradient information but instead sample in the vicinity of the original image to identify the least amount of noise needed to cause misclassification.
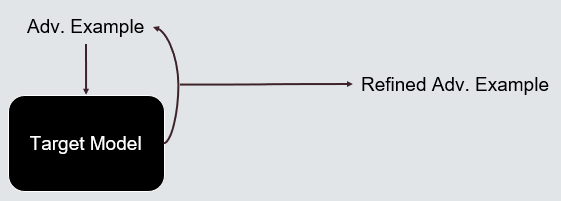 Decision-based Attacks(DEA)
Decision-based Attacks(DEA)
Decision-based attacks require patience and precision as they involve extensive sampling around the decision boundary. Understanding this can help in developing more robust defensive mechanisms.
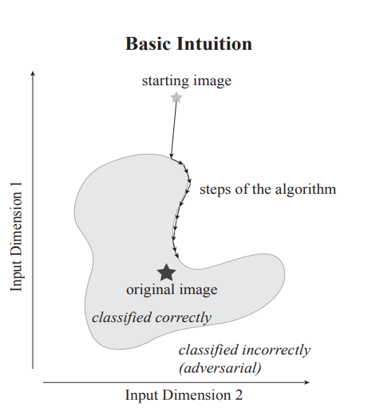
These attacks probe around the original image to identify the minimal noise required to induce misclassification.
 Boundary DEA Attacks
Boundary DEA Attacks
The process starts with the original input and aims to deceive the model into incorrectly classifying the input into a target category. It involves identifying the decision boundary that separates the target class from others and uses a perturbation vector that lies on this boundary and is perpendicular to it. The attacker then applies a binary search method to this vector to determine the smallest possible perturbation that leads the model to misclassify the adversarial example. This procedure is repeated until a successful adversarial example is created.
 Query Inefficiency due to DEA
Query Inefficiency due to DEA
While this method is efficient because it doesn’t require gradient computation, it does demand a significant number of iterations to converge and find adversarial examples. This iterative approach can lead to query inefficiency and potential pitfalls in the attack’s strategy. The attacks are not query-efficient, consistently sampling from a constant distribution without considering historical queries or the current noise context. Typically, the step size remains constant, which may not always be optimal.
 Local Optimum due to DEA
Local Optimum due to DEA
This approach can easily fall into local optima because it prefers adversarial examples with smaller noise magnitudes—a greedy search method that reduces later-stage efficiency. This inefficiency is often exacerbated by a model’s potential only to accept minimal adjustments, leading to stagnation in finding more effective adversarial examples as the attack progresses.
Transfer-Based + Decision-Based Attacks
In the realm of adversarial attacks on machine learning models, researchers have been innovating hybrid approaches that blend the strategies of both Transfer-based (TRA) and Decision-based (DEA) attacks. These hybrid attacks aim to leverage the strengths of each approach to enhance their effectiveness and efficiency.
Combining transfer-based and decision-based approaches can yield more effective adversarial attacks, but also opens up new avenues for defensive strategies. Staying informed on these developments is crucial for AI security professionals.
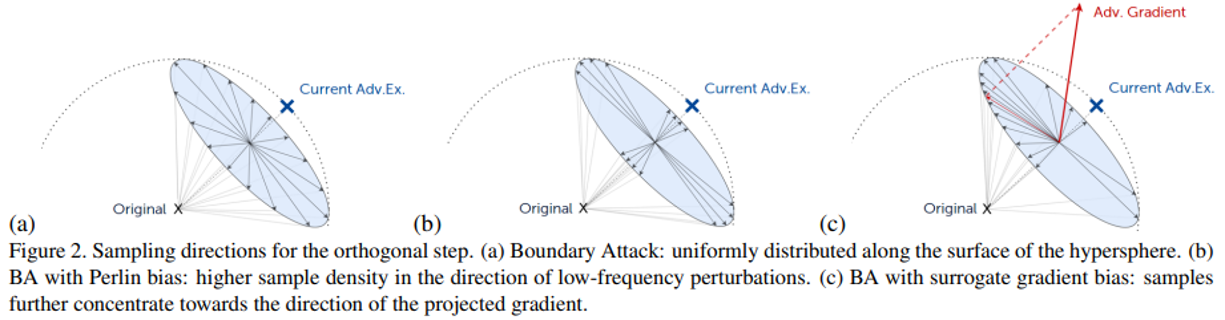
A notable example of such a hybrid approach is the Biased Boundary Attack (BBA) developed by Brunner et al.
 Biased Boundary TRA+DEA Attack
Biased Boundary TRA+DEA Attack
This method builds on the traditional boundary attack by initiating the adversarial sample much closer to the original input while ensuring it remains misclassified. The attack employs a biased random walk strategy, incorporating gradient estimation to assess the model’s loss function concerning the input image. This estimated gradient informs biased sampling, directing the search towards the decision boundary. Additionally, an adaptive step size is employed, which adjusts based on the success of previous steps, thus combining the gradient insights from TRA with the targeted probing of DEA for a more potent black-box attack method.
Other innovative hybrid attacks include Yang et al.’s Learnable Black-box Attack (LeBa) and Li et al.’s Query-Based Attack against Image Retrieval (QAIR). These methods primarily utilize one type of attack—either transfer-based or decision-based—to enhance or optimize the other, demonstrating the versatility and adaptability of hybrid approaches.
Further advancing this field, Shi et al. introduced a comprehensive black-box adversarial attack framework that incorporates elements of both TRA and DEA. This framework is structured around four distinct modules: the Parameter Adjustment Module (PAM), which sets up attack parameters to improve query efficiency and alleviate the overfitting problem common in TRA; the Transfer Attack Module (TAM), which generates intermediate adversarial examples based on parameters from PAM; the Noise Compression Module (NCM), which employs queries to find adversarial examples with smaller noise magnitudes by sampling near the original; and the State Transition Module (STM), which updates the adversarial example based on its classification status and proximity to the original image. Through this sophisticated integration, the framework aims to sidestep many of the pitfalls typically encountered in TRA and DEA, showcasing a strategic evolution in developing adversarial techniques.
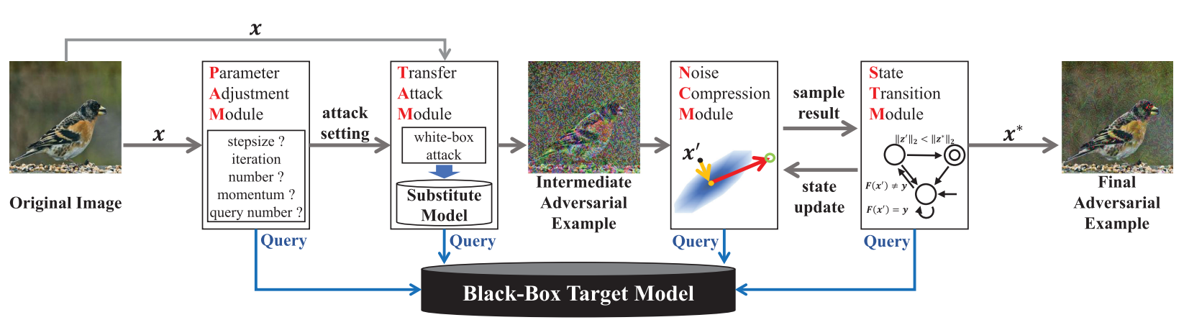 Query Efficient Black Box Adversarial Attack
Query Efficient Black Box Adversarial Attack
Conclusion
Adversarial attacks on neural networks highlight the ongoing battle between developing robust AI systems and the tactics used to undermine them. By dissecting and understanding the mechanisms behind these attacks, researchers can better devise methods to defend against them, ensuring the safety and reliability of AI applications across various domains. As we continue to integrate AI more deeply into critical systems, the importance of securing these systems against adversarial threats cannot be overstated.
References
- Shi et al. - Query-Efficient Black-Box Adversarial Attack With Customized Iteration and Sampling
- Goodfellow et al. - Explaining and harnessing adversarial examples
- N. Carlini & D. Wagner - Towards evaluating the robustness of Neural Networks
- J. R. Wieland Brendel and M. Bethge - Decision-based adversarial attacks: Reliable attacks against black-box machine learning models
- Brunner et al. - Guessing Smart: Biased Sampling for Efficient Black-Box Adversarial Attacks