Deepfake Detection using Deep Learning

Introduction
In our rapidly evolving digital age, the proliferation of advanced deep learning models has ushered in a transformative era of benefits across various sectors. Machine learning, a core component of artificial intelligence (AI), has become a cornerstone for enhancing technologies through automation, scalability, and unmatched pattern recognition capabilities. Today, almost every facet of technology I interact with has been or could be significantly improved with AI. Yet, like any powerful tool, AI holds the potential for misuse.
AI technologies, particularly in their capability to generate convincingly realistic media, pose unique challenges. One alarming development in AI misuse is the creation of deepfakes. These are hyper-realistic digital falsifications where AI-generated video or audio is overlaid or synthesized to impersonate someone, often without their consent. This technology can be exploited to create falsified forensic evidence or to discredit or defame individuals, undermining personal and public trust.
The implications of deepfakes extend beyond individual harm; they represent a profound socio-political threat by manipulating civil discourse, interfering with democratic elections, and challenging national security. On a more personal level, deepfakes can facilitate crimes such as pornography production, identity theft, and fraud, leading to severe psychological impacts on victims.
AI technologies, while beneficial, can be exploited for harmful activities such as spreading misinformation or committing fraud. Always be cautious of the source when encountering suspicious media.
Acknowledging these risks, there is an urgent need for research dedicated to identifying and curbing the proliferation of deepfakes before they inflict irreparable damage. A promising avenue in this pursuit is deepfake detection technology. This technique uses AI itself—trained on a mix of authentic and manipulated audio/video—to identify potential media manipulations effectively and rapidly, thus preventing potential harms.
In this project, I have developed a comprehensive and diverse dataset, unprecedented in scale, containing 1000 original video sequences from 977 YouTube videos alongside 1000 manipulated videos created using a Deepfake Variational AutoEncoder (DF-VAE). Utilizing this dataset, I trained a Convolutional Neural Network (CNN) model, aiming to set a new benchmark in deepfake detection capabilities and, ultimately, to enhance the security of digital content authenticity.
This paper details my methodology for assembling the dataset, describes each neural network model’s unique attributes, and presents a comparative analysis of their performance in deepfake detection. Through this work, I strive to make a significant contribution to the ongoing battle against digital deception, safeguarding the integrity of digital media for the future.
Literature Review for Deepfake Detection
Deepfake detection technologies are rapidly evolving to counteract the misuse of AI in creating fake media. These techniques vary in approach and complexity.
CNN-based Deep Learning Model
In the realm of digital forensics, traditional techniques often falter against the sophisticated manipulations seen in deepfakes, particularly due to data deterioration from compression. Jolly et al. addressed this challenge by proposing a robust deep learning model that combines Convolutional Neural Networks (CNN) for feature extraction with Long Short-Term Memory (LSTM) networks for analyzing video temporal sequences. Additionally, their model utilizes Recycle-GAN to integrate spatial and temporal data, significantly enhancing deepfake detection by considering both frame-level and sequence-level features. Employing the FaceForensics++ dataset, their model demonstrated high accuracy rates, outperforming several existing algorithms and proving particularly effective against various forms of deepfakes, including face swaps and facial reenactment.
Frame-based approach involving CNN
The increasing realism of deepfakes, facilitated by advanced generative techniques like Generative Adversarial Networks (GANs), presents growing challenges in detection. Ajoy et al. tackled this issue by developing a CNN model specifically designed to detect deepfakes by analyzing visual artifacts within video frames. This approach involves decomposing videos into frames, detecting faces, and scrutinizing them for inconsistencies such as pixel distortion, skin color discrepancies, and blurring. Validated using the DeepFake Detection Challenge dataset on Kaggle, their model achieved a notable validation accuracy of 85.8%, underscoring the potential of focusing on spatial and temporal data to enhance deepfake detection efficacy.
Multi-path CNN and Convolutional Attention Mechanism
P et al. highlighted the limitations of current deepfake detection methods, especially when confronting highly realistic videos created with novel techniques. They proposed a multi-path CNN approach leveraging three distinct architectures: ResNet, DenseNet, and InceptionResNet. This model employs a Convolutional Block Attention Mechanism (CBAM) to emphasize the most informative features, enhancing detection capabilities. Trained on the Deepfake Detection Challenge (DFDC) dataset, this approach achieved an accuracy of 94.0% and an F1-score of 93.9%, outperforming several baseline models. Their findings suggest that analyzing both spatial and channel-wise features through a multi-path approach can lead to more effective and nuanced deepfake detection.
High-Performance DeepFake Video Detection using CNN-Based Models with Attention to Specific Regions and Manual Distillation Extraction
Addressing the computational inefficiencies of current models, Tran et al. proposed a CNN-based approach that focuses on manual distillation extraction and specific regions within videos. This method reduces the learning burden by honing in on the most relevant features through preprocessing steps like face extraction, augmentation, and patch extraction. Utilizing frame and multi-region ensemble techniques, their model performed exceptionally well, achieving an Area Under the Curve (AUC) score of 0.958 and an F1-score of 0.92 on the DeepFake Detection Dataset, and even higher scores on the Celeb-DF. These results underscore the model’s accuracy and efficiency in detecting deepfakes by concentrating on the most pertinent elements.
A Hybrid CNN-LSTM model for Video Deepfake Detection by Leveraging Optical Flow Features
Saikia et al. shed light on the limitations of traditional deepfake detection methods, particularly their inability to capture the temporal dynamics of video frames. They developed a hybrid model that integrates CNN and RNN, specifically LSTM networks, enhanced by an optical flow-based feature extraction method that captures the temporal dynamics between frames. This model was tested across multiple open-source datasets, achieving accuracy rates of 66.26% on DFDC, 91.21% on FF++, and 79.49% on Celeb-DF. These results validate the effectiveness of their method against various deepfake types, highlighting the crucial role of temporal feature analysis in combating sophisticated deepfake technologies.
My Project
My model builds upon Ajoy et al. by using a dataset that breaks down videos into frames to analyze their visual artifacts. I used CNN on my comprehensive dataset to compare its performance and devise a straightforward approach to making deepfake detection more accessible and easier to train and deploy.
Breaking down videos into frames can make it easier to detect inconsistencies and artifacts that may indicate a video has been manipulated.
Project Implementation
As part of my effort to detect deep fake videos, I developed a deep learning model and tested it using data from two distinct datasets. In this section, I provide details about the datasets, preprocessing, model, and implementation.
Datasets
The datasets used in this project are critical for training and testing the deepfake detection models. Each dataset has unique characteristics that influence model performance.
I used data from two datasets for my project: FaceForensics++ and DeeperForensics-1.0.
- FaceForensics++:This dataset contains 1000 original video sequences from 977 YouTube videos. All videos feature a trackable front face without occlusions. We used these original videos for our training and testing data. The videos were downloaded from the FaceForensics++ Github with a C23 compression rate. (https://github.com/ondyari/FaceForensics/tree/master)
- DeeperForensics-1.0:This dataset comprises 11,000 manipulated videos created using various end-to-end face swapping methods and Deepfake Variational AutoEncoder (DF-VAE) methods. The dataset includes seven types of real-world perturbations at five different intensity levels. Our project utilized the 1000 raw manipulated videos generated by DF-VAE end-to-end. These videos were downloaded from the DeeperForensics-1.0 GitHub repository and can be found in the manipulated_videos_part_00.zip file. (https://github.com/EndlessSora/DeeperForensics-1.0/tree/master)
Preprocessing
The data preprocessing for the project involved a combination of 1000 original and 1000 manipulated videos. The project_3_preprocessing.ipynb file defined several functions to modify the videos. Additionally, the ffmpeg executable was used to change the encoding of the videos.
Effective preprocessing improves model accuracy by ensuring that the data fed into the neural network is consistent and of high quality.
The preprocessing was carried out in the following steps:
- Consistent Encoding: The original encoding of the videos was in C23, which was re-encoded to H.264 for easier handling and manipulation. This was done using the \textbf{ffmpeg} tool with the following command when the ffmpeg executable was in the dataset folders.
1
2
3
4
for %i in (*.mp4) do (
ffmpeg -i "%i" -c:v libx264 -preset medium -crf 23 "temp_%i"
move /Y "temp_%i" "%i"
)
- Renaming Videos: The
rename_videosfunction was used to rename the video files in a given directory. It extracted the first three characters of each filename and renamed the file accordingly. This was done to ensure that the naming of original videos was consistent with the naming of manipulated videos. - Trimming Videos: The
trim_videosfunction was used to trim each of the input videos to a maximum of 10 seconds long. This was done to ensure faster training and testing times and make each video consistent. - Extracting Frames: From the 2000 videos, each 10 seconds long, the
extract_framesfunction was used to extract nine frames, each evenly spaced 1 second apart. The frames were then stored as JPEG images in another folder. - Face Detection and Extraction: The
detect_facesfunction was designed to detect and extract faces from the extracted frames. It involved reading each frame, using the frontal face detector algorithm by the lib library to find faces, and saving them as separate images. - Loading Faces into Arrays: Finally, the images were loaded into a numpy array X using the
load_facesfunction, resizing them to (224,224). A corresponding label array y containing the corresponding labels was also generated. These were then split and used for training and testing the models.
 Frames of the Original Video
Frames of the Original Video  Faces extracted from the Original Frames
Faces extracted from the Original Frames  Frames of the Manipulated Video
Frames of the Manipulated Video  Faces extracted from the Manipulated Frames
Faces extracted from the Manipulated Frames
The figures above showcase an example of the preprocessing done on a randomly selected video in the dataset, both for the original and the manipulated videos.
CNN (Convolutional Neural Network) Model
Convolutional Neural Networks (CNN) are highly effective in image recognition tasks, making them suitable for detecting deepfakes. Our project used a sequential CNN designed explicitly for this purpose.
The CNN model used here is tailored for image and video recognition tasks, making it suitable for detecting deepfakes by analyzing spatial features.
To train the model, we randomly selected 80% of the dataset for training and used the remaining 20% for testing. Additionally, 10% of the training data was used for validation during the training process. The model was trained using a batch size of 32 over 50 epochs, but we implemented the early stopping callback to avoid redundant epochs.
The model consisted of Convolutional 2D, Batch Normalization, and Dense layers. ReLU activation, Max Pooling, Dropout, and Flatten were also used to detect deepfakes.
Here’s a breakdown of all the layers and hyperparameters used:
- Conv2D Layers: These convolutional layers are crucial for image feature extraction. Each layer uses a set of filters (32, 64, and 128 in each successive layer) to scan the input images and learn various features. The filter size (3x3 in this case) is standard for capturing local features like edges and textures.
padding=sameensures the output size is the same as the input size, preserving border information. - ReLU Activation: The Rectified Linear Unit (ReLU) activation function introduces non-linearity, allowing the model to learn complex patterns. It’s computationally efficient and helps avoid the vanishing gradient problem.
- Batch Normalization: This normalizes the previous layer’s output, reducing internal covariate shift, which helps in faster and more stable training.
- Max Pooling: These layers reduce the input volume’s spatial dimensions (height and width) for the next convolutional layer. It helps reduce the computational load, memory usage, and number of parameters.
- Dropout: This is a regularization technique to prevent overfitting. Randomly setting a fraction of input units (0.25 and 0.5) to 0 at each update during training helps make the model more robust.
- Flatten: This layer flattens the 2D arrays from the pooled feature maps into a single long vector. It’s needed before using fully connected layers.
- Dense Layers: These are fully connected layers. A dense layer with 128 neurons is used for further learning from the features extracted and flattened. The final dense layer with a single neuron and Sigmoid activation functions as the output layer, providing the probability of the input being a deepfake.
- Adam Optimizer: Adam is an optimization algorithm that can be used instead of the classical stochastic gradient descent procedure to update network weights iteratively. The learning rate is set to 0.0001, determining how big a step is taken during optimization.
- Callbacks: This model uses two callbacks: ReduceLROnPlateau, which reduces the learning rate when
val_losshas stopped improving, helping fine-tune the model and avoid overfitting, and EarlyStopping, which stops training whenval_losshas stopped improving, preventing overfitting and saving computational resources.
Combining these layers and hyperparameters in a CNN made it highly effective for Deepfake detection. The model learns hierarchical feature representations from the input images, which are critical in distinguishing between genuine and manipulated images. Using dropout and regularization techniques like Batch Normalization helps build a model that generalizes well on unseen data.
Performance
The model took 18 epochs to train with an Earlystopping callback. The training saw validation loss increase and decrease rapidly. The validation accuracy consistently increased, decreased between epochs 8 and 9, and then increased again. The training loss consistently decreased, while the training accuracy consistently increased.
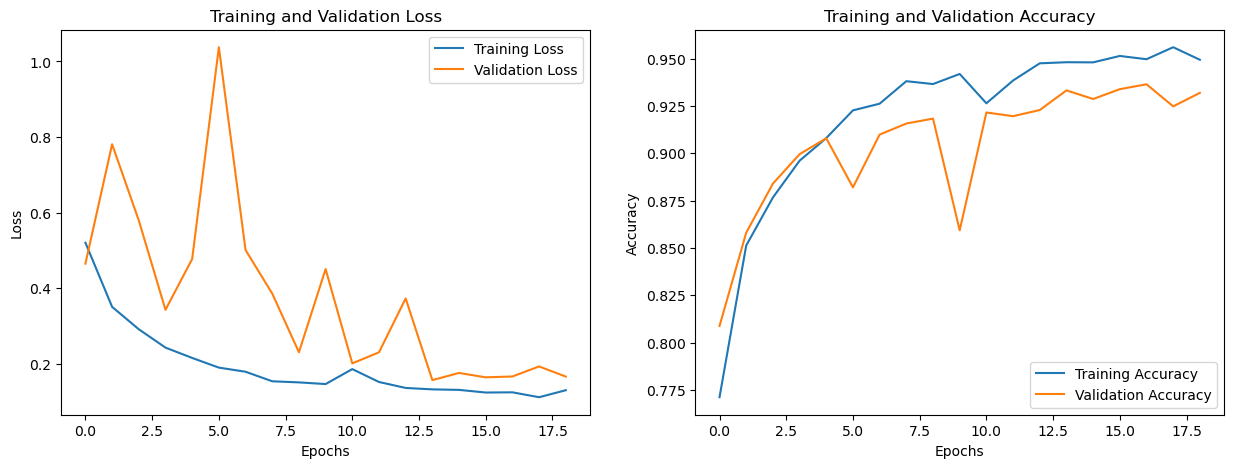 Training and Validation Loss and Accuracy of the CNN Model
Training and Validation Loss and Accuracy of the CNN Model
The figure above shows the model’s training and validation loss and accuracy.
On the 20% test dataset, the performance of the CNN model was as follows:
- Accuracy: (94.37%) This high accuracy score indicates that the model correctly classified approximately 94.37% of the test data. It strongly indicates the model’s effectiveness, especially in a binary classification task.
- Loss: (0.1346%) This is the model’s average Loss over the test data. A loss of 0.1346 is relatively low, suggesting that the model’s predictions are, on average, quite close to the actual values.
- F1 Score: (0.95 for Original and 0.94 for Manipulated)} The F1-score is a weighted average of precision and recall. Scores near 0.95 and 0.94 suggest an outstanding balance between precision and recall, which is often difficult to achieve, especially in imbalanced datasets.
- ROCAUC: (0.9891) The Receiver Operating Characteristic (ROC) curve is a graphical representation of a classifier’s performance, and the Area Under the Curve (AUC) provides an aggregate measure of performance across all possible classification thresholds. An AUC score of approximately 0.989 is excellent, indicating a very high level of separability between the classes. This means the model is very good at distinguishing between the two classes.
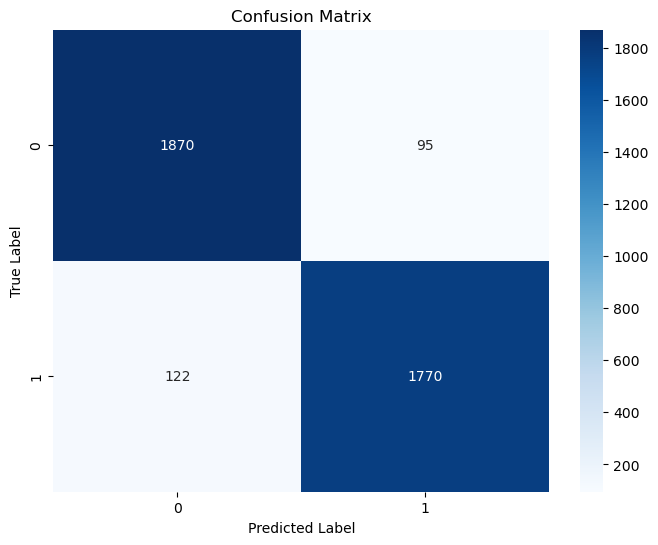 Confusion Matrix for CNN
Confusion Matrix for CNN
Conclusion
My project marks a significant stride in deepfake detection, achieving an impressive accuracy rate of over 90%. Our experiments underscored the superior efficacy of Convolutional Neural Networks (CNNs) in this domain.
The practical implications of these findings are far-reaching, offering robust tools for combating digital misinformation and enhancing content authenticity. However, I recognize the limitations of our current dataset and model configurations. Future explorations could incorporate a more diverse range of deepfake types and datasets, such as the DFDC dataset, to bolster the robustness of our models—encoder-decoder techniques, which have shown potential in deepfake detection, merit further investigation.
Despite advancements in detection, deepfakes are becoming more sophisticated. Continuous research and adaptation of detection models are necessary to keep up with evolving technologies.
I am acutely aware of the threat of concept drift, where newer, more sophisticated deepfakes could outpace current detection capabilities. Therefore, experimenting with advanced image extraction techniques, like InceptionV3 and ResNet, could enhance accuracy. Expanding my analysis beyond facial features to include other body parts may offer a more holistic approach to detecting deepfakes.
My work contributes a significant piece to the puzzle of digital content verification. As deepfakes continue to evolve, so must our methods of detection. I hope that this research not only advances the field technically but also catalyzes broader discussions on ethical AI usage and the protection of digital integrity in an increasingly virtual world.
Acknowledgement
This project was a joint effort with my skilled colleagues, Vaibhav Savala and Bala Volisetty. Together, we developed implementations of CNN, CNN + RNN, and GAN. We shared the dataset as part of our assignment for the CSEC-620 Cyber Analytics and Machine Learning course at RIT.
You can access the project by clicking here and my code by clicking here.
References
- Jiang et al. - DeeperForensics-1.0: A large-scale dataset for real-world face forgery detection
- Jolly et al. - CNN based deep learning model for deepfake detection
- Ajoy et al. - Deepfake detection using a frame based approach involving CNN
- P. et al. - Deepfake detection using multi-path CNN and convolutional attention mechanism
- Tran et al. - High performance deepfake video detection on CNN-based with attention target-specific regions and manual distillation extraction
- Saikia et al. - A hybrid CNN-LSTM model for video deepfake detection by leveraging optical flow features
- R ̈ossler et al. - FaceForensics++: Learning to detect manipulated facial images